E-mail
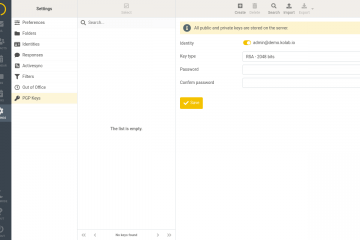
E-mail: Encryption with PGP
Kolab has configured Perfect Forward Secrecy (PFS), data in transport is encrypted with SSL/TLS, and all systems are HMS encrypted. The web client provides the option of encrypting emails through PGP asymmetric keys . As other similar solutions, e.g. the Read more…